Codemodding Python: unittest asserts to Python asserts

Originally posted at Medium.com
Large codebases require continued maintenance, but it is time-consuming and cumbersome to change portions of code scattered around many files. This article shows how to write codemods to refactor Python code using its Abstract Syntax Tree — gaining far more granular control than basic regex and search-replace.

The codemod is open-source on GitHub.
After writing numerous Django and unittest TestCases one become accustomed to the assert functions. These functions are however camelCased, and exposed on TestCase instances — requiring classes wrapping the tests. pytest introduced tests written in plain functions using regular asserts, which many prefer. It is however cumbersome and time-consuming to rewrite existing tests to cleaner asserts, so I decided to write a codemod that rewrites the unittest assert functions.
My goal:
self.assertEqual(variable_one, "variable_content")
self.assertTrue(variable_one)
⬇️
assert variable_one == "variable_content"
assert bool(variable_one) is True
The result:
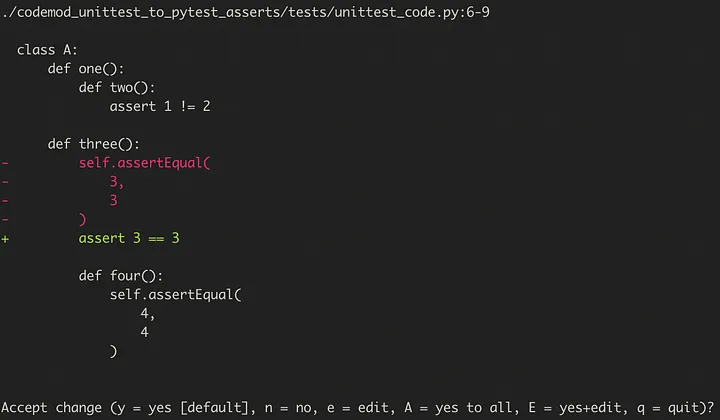
Implementation story
Codemod library
I started out by using Facebook’s codemod tool, which mainly exposes lines of text from specified files and enables us making Patch objects to rewrite specified lines in the file.
import codemod
def make_patches(list_of_lines):
patches = [...]
return patches
def is_py(filename):
"""
Filter method using filename's to select what files to evaluate for codemodding
"""
return filename.split(".")[-1] == "py"
def main():
codemod.Query(make_patches, path_filter=is_py).run_interactive()
if __name__ == "__main__":
main()
By running codemod.Query with a function make_patches as the first argument, the codemod library exposes all lines of text of each file as argument to that function - make_patches(list_of_lines). The path_filter allows us to filter what files that should be subject to modding, and here we simply grab the extension of the filename and returning True if it is a Python file. We simply execute the Python script and the codemod will recursively find the files in the working directory subject for modding.
Lastly the .run_interactive() method allows us to actively view and accept the changes suggested.
Parsing Python code
It is not straight forward to change each line that matches a certain structure using str.replace(), regex or similar. These assertions might be multi-line, have multiple arguments and so on. Therefore parsing the Python code into its Abstract Syntax Tree using ast enables us to more specific changes. Specifically, this enables us to easily extract the interesting bits from the nodes of the tree, for later to unparse it back to text. This makes it easy to handle arguments regardless of them being function calls spanning over 4 lines or just a simple string - since they are just nodes in a tree. We use these strings, along with line numbers, to build codemod Patch objects to replace lines in given files.
def make_patches(list_of_lines):
joined_lines = "".join(list_of_lines)
ast_parsed = ast.parse(joined_lines)
Traversing the AST
ast_parsed is at this point a tree of nodes, which makes it viable for known tree traversal algorithms. The ast package in Python provides a traversal (ast.walk) of the AST nodes, this means that one pretty much can do for node in ast.walk(ast_parsed). However, when implementing, it exhibited issues when trying to replace multiple lines with a single line. Since changing lines e.g. 7 to 10 into 1 line mean the line numbers below will deviate with 3. The patches created would then insert the code on wrong lines for subsequent patches. One might think that it would be possible to handle this by keeping count of the deviation, but looking at the ordering output from ast.walk it looked dangerously similar to BFS - which poses an issue.
class A(TestCase):
def one():
def two():
self.assertNotEqual(1, 2)
def three():
self.assertEqual(
3,
3
)
def four():
self.assertEqual(
4,
4
)
With BFS the node order would be one(), three(), two() and four(), which will become an issue when creating mod patches for each assert call step-by-step. We naively rewrite line 7-10 into one line at #7, meaning the lines below will deviate with a difference of three once hit.
class A(TestCase):
def one():
def two():
self.assertNotEqual(1, 2)
def three():
assert 3 == 3
def four():
self.assertEqual(
4,
4
)
At this point, we can store and subtract the deviation for lines below #7, but we should not subtract the deviation for the lines above. Using BFS the transform at #4 happens after #7 due to the order, meaning we cannot simply subtract the line deviation for all subsequent patches. For more complex cases it is especially cumbersome keeping track of deviations and different line numbers. One could after each Patch just save the file and reread the whole file with ast again, but a simpler and more performant solution is just to do DFS - because then we can guarantee the order. Storing and increasing the deviation (here = 3) would then work for all cases, despite complex nested structures. Then we can calculate the correct line number by subtracting the deviation from the current node's line number and increase the deviation by the difference for the next.
DFS is relatively simple to implement recursively, and AST provides a function iter_child_nodes to grab all the children of a node. Which actually is the same function ast.walk uses for its BFS queue implementation. Despite it implementing BFS, it turns out that ast.walk state that it does not guarantee the order of the nodes. However, my experiences show that this is not the case and that iter_child_nodes by default returns the direct children in the order of the line number. Our safety net is that these are tests we are modding, it would surely fail hard if it were any different.
def dfs_walk(node):
"""
Walk along the nodes of the AST in a DFS fashion returning the pre-order-tree-traversal
"""
stack = [node]
for child in ast.iter_child_nodes(node):
stack.extend(dfs_walk(child))
return stack
The resulting node order would now become one(), two(), three(), four() making the deviation deterministic. At this point, we can take the previous starting line of the assertion in four(), #12, and reduce it by the deviation of 3 into #9. We generate the line assert 4 == 4 from the node and place it at line 9 - then increasing deviation to 6.
class A(TestCase):
def one():
def two():
assert 1 != 2
def three():
assert 3 == 3
def four():
self.assertEqual(
4,
4
)
Modifying AST nodes
Since we have got ahold of the AST nodes, it is easier to extract the arguments from the function calls. I initially tried with regex, but again multi-lines, different numbers of arguments, keyword arguments and so on made the task pretty hard. By checking if the node is of instance ast.Expr and that its value is of instance ast.Call we can ensure that the node is a function call.
def node_get_call(node):
if isinstance(node, ast.Expr):
value = getattr(node, "value", None)
if isinstance(value, ast.Call):
return value
Having a Call node, one can grab the key attr and get the name of the function. E.g. assertEqual. We utilise this to figure out what kind of transformation we want to do, is it assertEqual we want assert X == Y etc.
def node_get_func_attr(node):
if isinstance(node, ast.Call):
return getattr(node.func, "attr", None)
By building a map over the assert functions we have implemented transformations for, we can easily grab the specialised function for the given function name. We execute this function with the Call node as the argument, since this node contains the arguments and keyword arguments required to perform the transformation.
assert_mapping = {
"assertEqual": handle_equal,
"assertNotEqual": handle_not_equal,
...
}
def convert(node):
node_call = node_get_call(node)
f = assert_mapping.get(node_get_func_attr(node_call), None)
if not f:
return
return f(node_call)
So at this point, we are calling tailored functions f separated by its function name with the arguments inside the parenthesis. E.g. assertSomething(arg, kwarg_one=1) where the function name is assertSomething, and the Call node contains arg and kwarg_one=1.
The arguments in the Call node are given in the attribute args and the keyword arguments are given in keywords. Since these are nodes (might be function calls!) to we need to unparse them into text, we do this by using astunparse, the inverse of ast. Furthermore, we put them into lists of strings, so that the argument list would become args = [1, 1] for assertEqual(1, 1). Using this we can build a modded string assert {args[0]} == {args[1]} => assert 1 == 1.
def parse_args(node):
args = []
kwarg_list = []
for arg in node.args:
args.append(astunparse.unparse(arg).replace("\n", ""))
for kwarg in node.keywords:
kwarg_list.append(astunparse.unparse(kwarg).replace("\n", ""))
return args, kwarg_list
def handle_equal(node):
args, kwarg_list = parse_args(node)
# Skip if args and kwargs are of unknown size
if len(args) != 2 or len(kwarg_list) > 0:
print("Potentially malformed")
return
return f"assert {args[0]} == {args[1]}"
So now we got our assertion string, and we want to insert it into our file. Using Patch from codemod, we can build patches by doing:
codemod.Patch(start_line, end_line, new_lines=assert_line)
We grab the start_line from the AST node by doing node.lineno, using Python 3.8 features we can also grab end_line using node.end_lineno. We subtract the line deviation from the start_line as described earlier, and add the transformed line into lines. However we also need to take the indentation in front of the assertion into account, luckily node.col_offset gives us the number of spaces in front of the node we are replacing.
converted_string = handle_equal(node) # "assert 1 == 1"
line_deviation = 0
assert_line = node.col_offset * " " + converted_string + "\n"
start_line = node.lineno
end_line = node.end_lineno
new_patch = codemod.Patch(
start_line - line_deviation - 1, # Off by one since we are inserting one line
end_line_number=end_line - line_deviation,
new_lines=assert_line,
)
line_deviation += end_line - start_line
Now we got our patch new_patch! We can put multiple of these into a list and return it to the make_patches method in codemod.Query(make_patches, ...]) and it will automagically suggest rewrites of the provided file or files.
Lastly
In the aftermath of building this, I figured that there might be better ways to accomplish this. One idea is to modify or generate and replacing the AST nodes themselves, then unparse the whole file. However, this was a decent and visual way to goal and a great learning experience built at a hackathon (and a little bit more) 😁
The codemod is pretty much stable without big issues and I have rewritten 189 files with +5,159 additions and −5,787 deletions in Oda’s codebase. One known issue is that it does not work properly if you skip multi-line patches due to the line deviation thing being naive, but that is generally not the case. Just mod everything and verify by running your tests!
If you want to use this codemod it is open source at GitHub under the MIT License: codemod-unittest-to-pytest-asserts. As mentioned there I advise you to use a formatter like black afterwards, since I naively just replace big multi-line functions into a single unformatted line.